Everything you ever wanted to know about Zookeeper
This blog post will discuss the research paper, Zookeeper: Wait-free coordination for Internet-scale systems. Click here for downloading the paper.
What problem does Zookeeper solve?
Coordination is of utmost importance in distributed applications. While building distributed systems, we need primitives like distributed lock services, shared registers, group messaging, etc. Instead of implementing these on our own, Zookeeper provides such primitives off-the-shelf.
It is like a library that you import in your code and write your own logic on top of it.
Keywords
Shared Registers
A shared (read-write) register, sometimes just called a register, is a fundamental type of shared data structure which stores a value and has two operations: Read, which returns the value stored in the register, and Write, which updates the value stored.
Source: Wikipedia
Distributed lock services
Distributed locks are required so that the system can agree on a particular state at any given time. They are required to maintain data integrity.
Wait-free mechanism
Clients’ requests are returned to them from the server and they(clients) don’t have to wait for the other slow clients and servers.
Event-driven mechanism
When the flow of control or flow of data is driven by the changes in state, that architecture is event-driven architecture.
Linearizability

I suggest taking two minutes out and reading this article on Wikipedia to better understand what linearizability is. In the context of this paper, linearizability is like a world-clock fort the distributed system. So, if a write succeeds, then all the reads that arrive after that write will see the changes. The leader in ZK enforces Linearizability.
Zookeeper is a coordination kernel using which you can build new primitives without changing your core service. Many distributed
So, it is safe to say that Zookeeper solves the “master” problem. It acts as a centralized serialization point.
Zookeeper Design

Primitives can be either blocking or non-blocking. ZK provides API of non-blocking primitives. ZK aims at ensuring high throughput. With blocking primitives being exposed via APIs, the whole system becomes a lot more complicated as all the requests awaited by clients are dependent on the responses and availability of other clients. Thus, ZK uses wait-free APIs that expose a tree structure of data objects. Through this, it achieves performance and fault-tolerance.
If using ZK, the distributed system implements replication to achieve high-availability and performance.
In order to achieve coordination, ZK enforces two methods: i) FIFO client ordering ii) Linearizability.
Clients using ZK can issue their requests asynchronously and ZK will use FIFO order to process those requests. This ensures coordination amongst the nodes.
So far, we have seen how the design of ZK achieves high performance, high-availability, fault-tolerance, and coordination.
Zookeeper as a Service
Client — user of ZK service
Server — Process providing ZK service
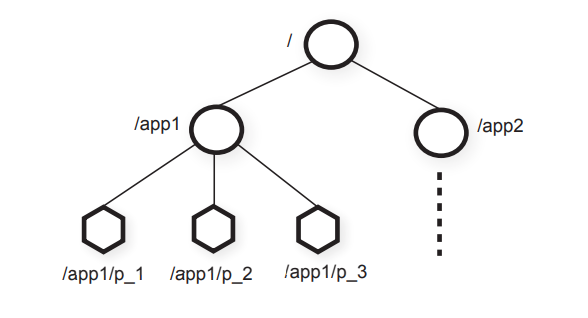
znode — in-memory data node that is a tree structure. znode is used to represent data objects in their actual hierarchy.

“My-code” uses ZK APIs. Process P1 and P2 serve these APIs to the client(“My-code”). If you notice the tree box in the bottom right corner, that is the ZK’s hierarchical namespace.
Each node in that tree is called znode.
The figure shown below is an actual representation.
Clients can create two kinds of znodes: regular and ephemeral.
While creating a znode, the client has to name it. Naming can be manual or sequential. In the sequential case, it will be something like this — > a/b/1, a/b/2, …
ZK does not use polling to detect changes in this tree. Instead, it uses watches. Polling is a pull-based mechanism whereas watches implement the push-based mechanism.
Why a tree-like structure and not a flat structure of data objects?
If there exists a tree-like structure, the hierarchical namespace can be used for allocating subtrees for different applications. Also, it makes access to control possible. This is exactly the same kind of implementation in the UNIX filesystem. Note: znodes store metadata, mostly for coordination purposes. ZF is not a data storage system. Since data size is so less, this tree is stored in memory.
ZK uses sessions to keep a channel of clients open. The session expires when the client turns out to be faulty or when the client explicitly ends the session.
When does a client turn out to be faulty?
If the server doesn’t receive anything from the client for the timeout duration, the server marks the client as faulty.
Each znode has a timestamp, version, single-user data item.
Client APIs
- create(path, data, flags); • delete(path, version); • exists(path, watch); • getData(path, watch); • setData(path, data, version); • getChildren(path, watch); • sync(path);
create(path, data, flags) : create a znode at a given path, store the data in it, create it an ephemeral or a regular znode with sequential flag on/off. In return, you get the path of the node.
delete(path, version): if version matches, delete the node at that path.
exists(path, watch): if the node exists at that path, return true otherwise false, also, if the watch parameter is set, the client will get notifications about the changes in that znode from now on.
getData(path, watch): returns the data and metadata, set the watch if the flag is set.
setData(path, data, version): if the version matches then write data on that path.
getChildren(path, watch): returns the subtree of that path.
sync(path): This is an interesting feature. ZK is asynchronous by default. So, it is possible that the client sends a write and then tries to read something. Another client issues a read after the first write was sent. Now, it may take some time for all the replicated ZK trees to be updated and so, it is possible for a client to read while there is a pending write, making it a stale read. If sync function is called, ZK ensures that all the pending writes are processed and then the following reads are executed.
Zookeeper Guarantees
Linearizable writes
Explained above in detail, the leader ensures that all the writes are processed in the order. Servers send write requests to leader and leader enforces them in their sequence of arrival.
FIFO Client Order
The client’s requests are processed in the exact same order as generated.
Atomicity
Just like other consensus protocols(Raft, Paxos, etc), all the updates in the system are transactional, there is no partial update.
Reliability
All updates that are successful will persist as they are applied to the majority and they will never be rolled back.
Scenarios to understand Leader election and configuration management in Zookeeper
Consider there are one leader and 3 servers(followers) in the current ZK system. Suddenly, the leader dies due to some reason. Now, the new leader will be elected but it has to modify all the configuration files before any worker reads them. To ensure this, ZK makes the workers read the config only if there exists a “ready” znode. So, when the leader dies, the new one gets elected and it deletes the ready znode at first. This makes the configuration files inaccessible by the workers. Now, the new leader updates the configuration and then creates the ready znode following which all workers are able to read the updated configuration.
Zookeeper as a Lock Service
This is how ZK implements a single lock:

Such logs are used for synchronization purposes.
This is how ZK implements read/write locks:

Now it may be obvious to you as to why stale reads are possible in ZK. As you can see in line #3 in Read Lock algorithm, if there are no pending writes, the server can read from local storage. This also explains the weak consistency model of ZK. Although using sync() API of ZK, you can ensure strong consistency model.
Summary

The above image is taken from the paper, to summarize all the components involved in ZK. Atomic Broadcast is nothing but a fancy term for consensus protocol. ZK uses zab as the consensus protocol which is similar to RAFT.
Kudos if you realized the following on yourself and can provide a reason for the same in the comments:
ZK won’t encounter a split-brain problem even though it has replicated servers.
