How Data Modeling and ETL designs are important for designing a Data Warehouse?

While working with big data sets, I have found designing ETL systems really easy when those data sets are for a customer. However, when working with data sets with B2B customers, the data sets are so diverse that it is almost impossible for me to perceive all the queries(kinds) analysts would want. Hence, I started reading this book about building a data warehouse by Kimball and Ross. It has provided me a fresh and new perspective, having empathy for the data analysts and business analysts. So, here s my blog post, sharing my learnings in a synthesized way. I want to explain how and why data modeling is useful while designing ETL systems.
Some prerequisites to know(just the google definition would do):
- Fact tables
- Primary key
- Foreign key
- Data Warehouses
- ETL
The Gurus/Gods of Data Warehousing, Kimball and Ross defined the following goals for a data warehouse:
- The DW/BI system must make information easily accessible
- The DW/BI system must present information consistently
- The DW/BI system must adapt to change
- The DW/BI system must present information in a timely way
- The DW/BI system must be a secure bastion that protects the information assets
- The DW/BI system must serve as an authoritative and trustworthy foundation for improved decision making
- The business community must accept the DW/BI system to deem it successful
Presenting information consistently, timeliness, and adaptability all are achieved in ETL processes. You design your ETL well and keep business logic in mind, you have achieved major goals of a data warehouse. This is challenging and not something that you can achieve by just mastering Airflow.
But how do we achieve accessibility?
ETL is not doing anything for me other than just pulling the data, transforming it and loading it in my DBs where I can query it. You would say that Transformation would have me achieve accessibility but there are cases which we will see later where T can’t be used to achieve accessibility. Even if you do want to achieve it, you” ll have to model your data and then apply transformations to have that desired data modeling. Thus, data modeling is required to achieve accessibility. In other words, T is not only transformations on the data that you want to present, but it could also be data modeling for future use cases.
Before we think or get into ETL and data modeling, let us recall the primary objective of building a data warehouse: to make it straightforward and unambiguous — “easy” — for analysts to write analysis queries quickly and effectively. You can assume that the end-user will be able to write SQL queries but you cannot and should not assume that they will be writing complex outer joins, grouped subqueries, using primary-foreign key relations, recursive queries, etc.
What we should expect from our Business and Data analysts:
- Only simple joins
- descriptive columns
- the ability for correct aggregation(yeah, aggregate is one function which is going wrong so frequently and so easily that you can’t even imagine)
- querying data both on granular and at the larger level: for eg, year-wise, day-wise, hour wise, quarter wise, etc.
- the uniqueness of data guaranteed when asked for(SELECT DISTINCT)
So, the world moved from OLTP to Facts and Dimensions long ago but I still feel that we don’t adhere to the philosophy of dimensional data modeling as much as we should do — in the same way that we don’t use UML diagrams as much as we should do.
Transactional Databases and data movements
We often design our data systems while keeping in mind the retention of data and we end up losing so much on the accessibility. We should understand that the real use case of your app or product is transactional — order placed, order received, etc but the analysis that you are going to do for the sake of your business is rarely going to be transactional. You got to aggregate or analyze to discover information about the functioning of the business processes. And so, you have to ensure that there is no overlap in b/w two events that you recorded in your transactional database otherwise the aggregation would be wrong, irreversibly wrong.
If your data captured is having primary keys, you are all set. But that is not always the case. I have seen so many datasets that are really crucial for business logic but they have no primary key. In such cases, amateur as I was(am), I allowed the duplicates or I considered the hash of all the columns combined as the primary key. Even then, you would have duplicates but that’d be alright mostly because I inserted two exact same rows once. None of these are the ideal solutions or solutions at all. You have to have something using which you remove redundancy. And so, we use different dimensions of the data in order to capture unique rows.
Transactions/Facts are not going to give you insights
One perfect example would be Indian Premier League tickets sales. You record tickets sale and their price but you end up running analysis on maximum money earned w.r.t a team, which weekdays are most profitable, etc. So, these are the measures that you want to derive from your facts(in fact table). Enter the concept of filling measures in your data.
Need of Granularity
It is always preferable to have as much atomicity as possible. But data is not kind: you can have sales in dollars per hour and sales in INR per quarter. And I challenge you to convert both of them at the same rate and gain some insights. And so, we need Periodic and Accumulating snapshot tables in order to have data at some granularity.
Taking the summary from Kimball and Ross:
Periodic Snapshot Fact Tables
Periodic snapshot tables are collected at regular time intervals. Consumption of some resource, like water or electricity, are the natural case for periodic snapshots. However, there are also periodic snapshots that are essential audits. The summary in a bank account statement is that kind of periodic snapshot: starting balance, ending balance, interest. (Not, of course, including the details, that is, the transactions.)
Accumulating Snapshot Fact Tables
One business question that may be difficult to answer in business intelligence is the passing of time between facts. If you’ve ever seen the timers in a restaurant drive-through, you know that companies can find this very important. But if you take the atomic-grained fact of your ordering a fish sandwich and the fact of the bag being handed through the window of the car, you can’t assess performance. That timer on the wall knows, but you don’t. When a business performance indicator is the rate of completing a multi-step business process, you may want to capture at the grain of the entirety of the process and record the start, the completion, and the steps in between. This may be transaction-grained, but it has a lot of measures in between.
Locating Facts using Dimensions
I would like to recall our main objective: driving business intelligence.
In order to query the fact tables and get some business insights, you have to consider the information provided by the dimension tables. Thus, it is important for you to know how you can leverage the dimensional modeling and query the facts.
We search the table by searching the dimensions in which we are interested.
Kimball and Ross introduce dimension tables as “descriptive context,” the “who, what, where, when, how, and why” of a fact.
Using the Star Schema
We have taken this schema for granted, so much that we often mess up our design and our data warehouse gets off its track. If we keep checking our dimensional modeling, we are way better off than just de-normalized or normalized database design.
One of the interesting aspects of dimensional modeling is that, in some ways, the fact table is most clearly defined not by its primary key, or any unique identifier, but the combination of dimensions it carries. That is to say, each fact is identified as the unique intersection of values in each of its dimensions.
While there is often some sort of identifier that can serve as a primary key in a fact table, standard data warehousing practice creates the primary key as a composite of all the dimensions it carries. That is, for any combination of the dimensions, there is exactly one fact record, with measures that can be aggregated and analyzed, for example, in conjunction with other records sharing the same values or ranges of those dimensions.
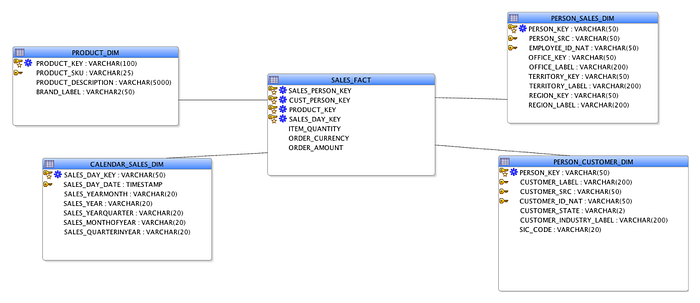
Why do you have to make your dimensions into a compound PK for your fact table?
Because if you do this, all of your querying, and all of your reporting, will come down to choosing values or ranges of dimensions to query, and aggregate facts across them. When you get to queries across facts, duplicates among dimension combinations will turn into a disaster.
A checklist, again taken from Kimball and Ross, that should be used while data modeling:
- The Value and Necessity of Dimensions’ Uniqueness in Facts
- Add or Aggregate Dimensions to Make Facts Unique
- Hierarchy in Dimensions
- Adding Columns to Group Ranges of Distance
- Check whether there is a people dimension(Driver, Client, Contractor in Uber).
I hope this article brought a lot of obvious rules back in your conscious. Please give me feedback on this article and if you have something neat to work on, let me know: avi.srivastava254084@gmail.com
